Welche Wissensarchitektur KI im Unternehmen braucht
Die meisten Organisationen, die KI-Piloten starten, bauen sie auf einer Wissensbasis, die schon vor der KI nicht funktioniert hat — Kanzleien, Steuerberatungen, Beratungsbetriebe genauso wie Rechtsabteilungen, Strategie, R&D oder Einkauf in größeren Konzernen. Die These dieses Beitrags: Wer sein Wissen nicht vorher aufräumt, bekommt mit KI keinen Hebel, sondern eine schnellere Suchmaschine. Das Aufräumen besteht aus drei klar getrennten Schichten, zwei Regeln darüber, zwei Rhythmen und vier Menschen, die Verantwortung tragen. Mehr nicht. Weniger geht auch nicht.
Gleicher Mandant, zweiter Auftrag, drei Jahre später. Die Partnerin sitzt am Telefon und weiß noch, dass es damals Streit um eine Haftungsklausel gab. Aber den genauen Wortlaut? Liegt in einer Mail von damals, und der Kollege, der sie geschrieben hat, ist gerade im Urlaub. Das Team fängt halb von vorne an. Das Beispiel steht für ein wiederkehrendes Problem kontextabhängiger Wissensarbeit. Im Konzern heißt die Szene anders, aber die Mechanik ist dieselbe: Die Leiterin der Steuerabteilung sucht die Unterlagen zur letzten Betriebsprüfung einer Tochtergesellschaft. Der Head of Strategy will wissen, warum ein Markteintritt 2022 abgeblasen wurde. Der Compliance-Officer braucht den Vorgang, der vor drei Jahren ähnlich gelagert war. In allen Fällen liegt die Antwort irgendwo zwischen einem SharePoint-Ordner, einer Mailbox und einem Kopf, der gerade nicht greifbar ist. Das Wissen, das den Unterschied macht, lebt in Personen — und jeder Wechsel ist ein stiller Verlust.
Das ist nicht neu. Neu ist, dass KI diese Schwäche skaliert. Ein Agent kann einen hundertseitigen Vertrag in neunzig Sekunden prüfen — aber nur, wenn er weiß, was bei diesem Mandanten eine harte Linie ist, was in den letzten zwei Jahren verhandelt wurde, welche Klausel nie akzeptiert wird. Wer dieses Wissen nicht strukturiert ablegt, bekommt eine KI, die schnelle Antworten liefert, aber die internen Maßstäbe, die Historie und die Grenzen des Hauses nicht kennt.
Warum rutschen dann so viele KI-Initiativen in genau diese Falle? Weil der Reflex lautet: Wir brauchen ein besseres Tool. Ich verstehe den Reflex. Aber das Tool ist nicht die Engstelle. Die Engstelle liegt eine Ebene darunter — bei der Frage, wie das Wissen im Betrieb überhaupt abgelegt, geprüft und wiederverwendet wird. Eine Ablage liefert nur Antworten auf Fragen, die jemand direkt stellt. Ein Gedächtnis erinnert auch an das, woran niemand mehr gedacht hat. Genau dieser Unterschied wird zum Vorsprung, wenn dieselben KI-Werkzeuge für alle Häuser verfügbar sind.
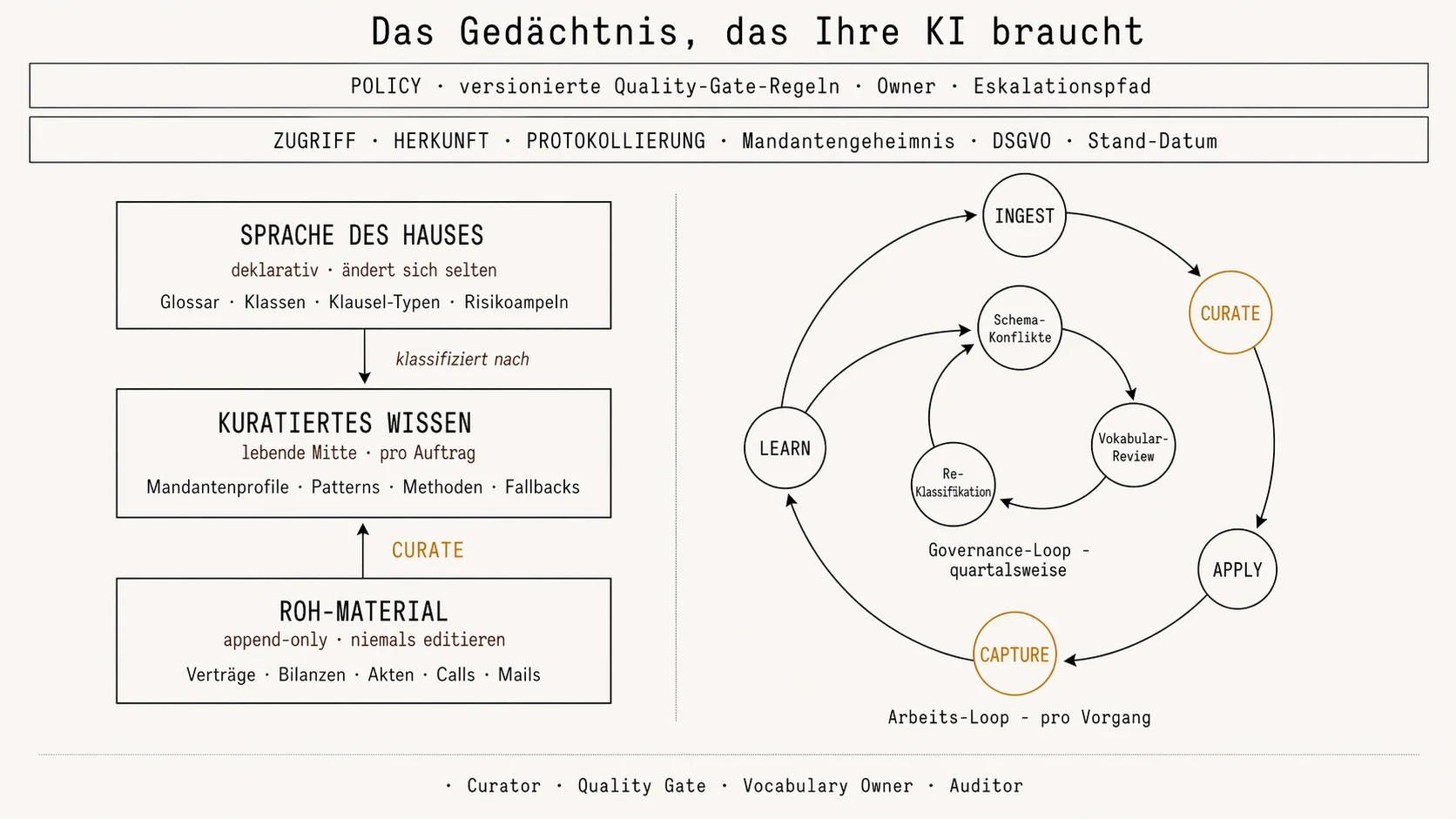
Drei Wissensschichten, die auseinandergehören
Das Bild oben zeigt den Vorschlag auf einen Blick. Der Kern: In jeder solchen Organisation — Kanzlei, Beratung, Steuer, interne Fachabteilung — vermischen sich drei völlig verschiedene Arten von Wissen im selben Ordner, derselben SharePoint-Struktur, demselben neu gekauften Tool. Genau diese Vermischung ist das eigentliche Problem.
- Die Sprache des Hauses. Was heißt bei uns „harte Haftungsklausel“, „kritischer Lieferant“, „hochriskantes Projekt“? Welche Risikoampel gilt für welche Branche oder welches Land? Welche Phasen hat ein Projekt, ein Audit, ein Markteintritt? Das ändert sich selten und lebt in den meisten Häusern in zwei, drei erfahrenen Personen. Solange das so ist, weiß niemand — auch keine KI — ob zwei Mitarbeiter das Gleiche meinen, wenn sie „kritisch“ sagen.
- Das Wissen aus jedem Vorgang. Muster, Ausweichpositionen, Methoden, Mandanten- oder Geschäftsbereichs-Profile. Das wächst mit jedem Auftrag, ist der eigentliche Wettbewerbsvorteil — und verschwindet anteilig mit jedem Seniorwechsel.
- Das Rohmaterial. Verträge, Bilanzen, Mails, Calls, Betriebsprüfungs-Akten, Audit-Berichte. Das wird archiviert, nie überschrieben. Nur so lässt sich später nachweisen, woher eine Aussage kommt, und nur so übersteht die Wissensbasis einen Audit.
Die Trennung wirkt banal, wird in der Ablagepraxis aber häufig nicht sauber durchgehalten. Wer die drei Arten auseinanderhält, schafft eine Wissensbasis, aus der KI belastbar ableiten kann. Wer sie vermischt, bekommt eine etwas schnellere Suchmaschine.
Zwei Regeln: Freigabe und Herkunft
Über diesen drei Schichten liegen zwei Regeln, die oft vergessen werden, weil sie langweilig klingen. Beide sind nicht verhandelbar — und beide werden irgendwann geprüft.
- Wer entscheidet, was in die Wissensbasis aufgenommen wird? Nicht die KI. Eine benannte Person mit Vetorecht. Ohne diese Rolle kippt die Qualität binnen Monaten, und zwar genau dann, wenn alle denken, es läuft.
- Wer garantiert Mandantengeheimnis und Nachvollziehbarkeit? In Kanzleien und Steuerberatungen ist das Berufsrecht, nicht Komfort. Ein Mandat darf nie Spuren in einer Antwort zu einem anderen Mandanten hinterlassen. Jeder Eintrag muss wissen, von wem er stammt und wann er zuletzt geprüft wurde. Technisch heißt das: Trennung muss durchgehend sein — von Zugriffsrechten auf Quell-Dokumente bis zu mandantenscharfen Prompt-Templates. Eine einzelne Schicht reicht nicht.
Die Governance-Entscheidung ist nicht vollständig frei: Je nach Organisation prüft später ein Dritter — Anwaltskammer, Datenschutzbehörde, der Mandant nach einem Vorfall, im Konzern die interne Revision. Wer es dann nicht nachweisen kann, hat ein Problem.
Zwei Rhythmen: wöchentlich verdichten, quartalsweise prüfen
Eine Wissensbasis ist keine Datenbank, die man einmal befüllt und dann vergisst. Sie lebt nur, wenn zwei Bewegungen gleichzeitig laufen:
- Wöchentlich. Neues aus dem Tagesgeschäft wird verdichtet und aufgenommen — bewusst, nicht automatisch.
- Quartalsweise. Jemand prüft, ob die Sprache des Hauses noch zur Realität passt. Neue Klauselarten, neue Branchen, verschobene Prioritäten. Das Vokabular muss mitwachsen.
Fehlt der zweite Rhythmus, arbeitet das System nach zwei Jahren gegen eine Welt, die nicht mehr existiert. Konkret heißt das: Ein neuer Klauseltyp taucht im Markt auf, die KI hat keine passende Kategorie, ordnet ihn der nächstbesten zu — und damit auch dem dort hinterlegten Risikoniveau und Standard-Vorgehen. Niemandem fällt es auf, bis bei einem konkreten Mandat ein Risiko übersehen wird, das im richtigen Schubladensystem sofort sichtbar gewesen wäre.
Vier Verantwortlichkeiten besetzen
Eine Wissensbasis dreht nur, wenn vier Rollen besetzt sind — und zwar mit mindestens drei Köpfen. Verdichter und Freigabe dürfen nicht dieselbe Person sein, sonst fehlt das Vier-Augen-Prinzip an der entscheidenden Stelle. Der Prüfer steht immer unabhängig von der operativen Linie, sonst ist die Kontrolle wertlos. Allein der Sprachverantwortliche kann in kleineren Häusern vom selben Senior mitgetragen werden, der auch die Freigabe verantwortet — ideal ist das nicht, aber tragbar. Die Mechanik in allen vier Rollen ist dieselbe: Die KI liefert Rohmaterial und Vorschläge, der Mensch entscheidet. Nicht umgekehrt.
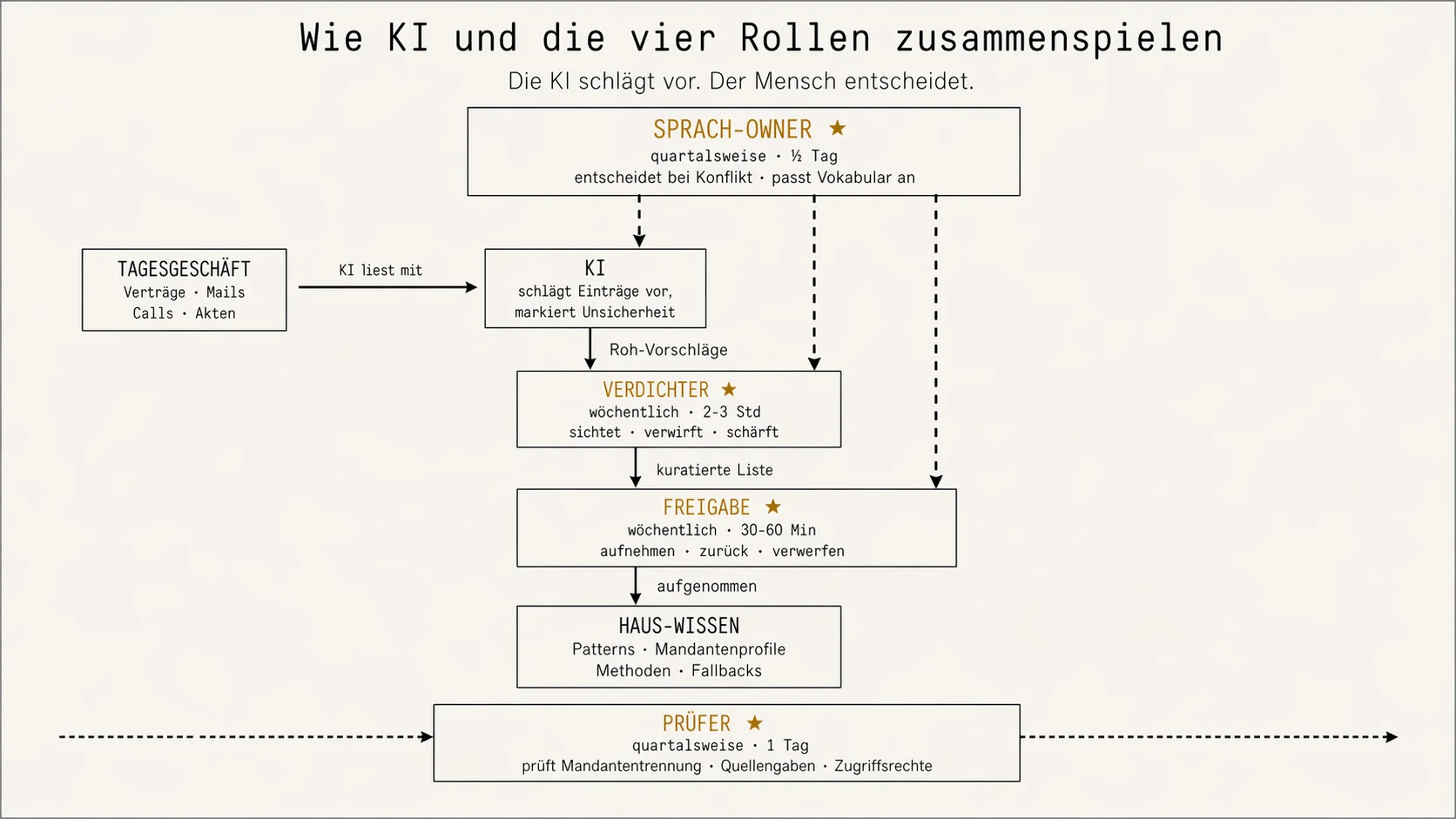
- Der Verdichter. Die KI verarbeitet die abgeschlossenen Vorgänge der Woche — neu unterschriebene Verträge, beendete Verhandlungen, abgeschlossene Mandatsabschnitte — und schlägt ihm daraus Einträge für die Wissensbasis vor: „Aus diesem Vertrag könnte eine neue harte Linie bei Mandant X werden", „Diese Formulierung taucht zum dritten Mal auf, eigenes Muster?". Er sichtet die Vorschläge, verwirft die Hälfte davon, schärft die Formulierung der übrigen, klassifiziert sie und legt eine kuratierte Liste zur Freigabe vor. Zwei bis drei Stunden pro Woche, feste Zeitfenster.
- Die Freigabe. Ein Senior mit Vetorecht. Sieht nur die vom Verdichter kuratierte Liste — nicht die KI-Rohvorschläge — und entscheidet pro Eintrag: aufnehmen, zurück zum Verdichter, verwerfen. Dreißig bis sechzig Minuten pro Woche, weil die Vorarbeit beim Verdichter liegt. Hier wird Qualität verteidigt, nicht verwaltet — und hier wird die KI davon abgehalten, ihre eigenen Halluzinationen zu Lehrmaterial zu machen.
- Der Sprachverantwortliche. Strategische Rolle auf Partner- oder Prinzipal-Ebene. Drei konkrete Signale, die er aus dem System bekommt: Erstens, die KI hat den Vorschlag selbst als unsicher markiert — ein heuristisches Signal aus dem Modell, keine kalibrierte Wahrheit über das eigene Wissen, aber für die Aussortierung zweifelhafter Fälle ausreichend. Zweitens, die Freigabe hat in mehreren Fällen die Klasse korrigiert, die die KI vorgeschlagen hatte (etwa von „mittleres Risiko" auf „hoch"). Drittens, ein neuer Begriff aus mehreren Mandaten passt in keine bestehende Klasse — Hinweis, dass eine neue Kategorie fällig ist. Das ist keine Selbsterkenntnis der KI, sondern schlichte Protokollführung: Jeder Vorschlag wird mit diesem Unsicherheits-Marker abgelegt, jede menschliche Korrektur ebenso. Was häufig als unsicher markiert oder überstimmt wurde, fällt im Bericht von selbst an. Der Sprachverantwortliche entscheidet: Vokabular anpassen, neue Klasse einführen, Grenzfall definieren. Ein halber Tag pro Quartal.
- Der Prüfer. Unabhängig von der operativen Linie, berichtet an die Partner-Ebene oder den Vorstand. Bekommt vom System einen Audit-Report: Einträge ohne Quellangabe, Einträge, deren letzte Prüfung zu lange zurückliegt, Zugriffe, die nicht zur Mandatszuordnung passen. Er bewertet, was zurück in den Workflow muss. Ein Tag pro Quartal. Die einzige Rolle, die per Konstruktion niemand anderem gefallen muss.
Die Eskalationskette in einem Satz: Verdichter schlägt vor, Freigabe entscheidet, Sprachverantwortliche überstimmt bei Bedarf, Prüfer kontrolliert alles unabhängig. Fehlt eine dieser vier Stellen, entsteht an genau diesem Punkt eine Qualitäts- oder Nachvollziehbarkeitslücke — und zwar meistens in dem Moment, in dem das erste ernste Mandat daran hängt.
Gedächtnis prüfbar betreiben
Damit aus der Wissensbasis ein belastbares Unternehmensgedächtnis wird, müssen Einträge versioniert, Quellen verknüpft und Zugriffe protokolliert werden. Das System sollte sichtbar machen, welche Einträge ungeprüft, veraltet oder unsicher sind. Erst wenn Rollen, Rhythmus und Nachweisführung stehen, ist die Toolfrage sinnvoll gestellt.
Drei Fehler, die sich wiederholen
- Das Tool kommt zuerst. „Wir haben jetzt eine Copilot-Lizenz, also fangen wir an." Ohne die vorgelagerte Klärung, wer welche Rolle trägt und wie die Sprache des Hauses aussieht, bleibt das Tool am Ende nur eine teure Ablage. Das Tool ist die letzte Entscheidung, nicht die erste.
- KI darf direkt ins Haus-Wissen schreiben. Der schnellste Weg, die eigene Wissensbasis zu vergiften: Halluzinationen werden zu scheinbar belegtem Lehrmaterial, und die nächste KI-Antwort zieht ihre Autorität genau daraus. Dagegen schützt nur eine menschliche Freigabe, kein technischer Filter.
- Ein Senior pflegt alles nebenbei. Wenn diese Person geht, bricht das System an der zentralen Stelle weg. Verteilte Verantwortung sichert das Haus gegen den Verlust eines substanziellen Teils seines Gedächtnisses beim nächsten Abgang.
Warum dieses Bild und nicht ein anderes
Der Ansatz ist nicht neu. Andrej Karpathy — ehemaliger Chef-Ingenieur für KI bei Tesla und Mitgründer von OpenAI — hat im April 2026 ein „Idea File ↗" für eine LLM-kuratierte Markdown-Wissensbasis veröffentlicht: keine Vektor-Architektur, keine reine Embedding-Schicht, sondern strukturierter Markdown als verbindliche Wissensquelle. KPMG hat parallel eine Enterprise-Variante ↗ beschrieben, die auf drei Bausteinen aufbaut: Bedeutungsschicht, Ontologie und Wissensgraph. Beide kommen unabhängig voneinander zum gleichen Bild, für sehr unterschiedliche Unternehmensgrößen. Was in dieser Fassung dazukommt, ist die eigene Erfahrung beim Aufbau einer Wissensbasis: die Trennung von Vokabular und Regelwerk, die zwei Rhythmen, die vier Rollen, die typischen Fehler.
Mein Punkt ist dieser: KI-Assistenten werden austauschbarer, wenn dieselben Modelle über ähnliche Oberflächen und Preismodelle verfügbar sind. Was die Häuser unterscheidet, ist nicht der Assistent. Es ist das Gedächtnis, das sie ihm mitgeben. Und dieses Gedächtnis entsteht nicht, wenn die nächste Lizenz freigeschaltet wird. Es entsteht, wenn ein Haus anfängt, sein eigenes Wissen ernst zu nehmen — strukturiert, verantwortet, nachvollziehbar. Davor gibt es keine Abkürzung. Wer anderes verspricht, verkauft meist Lizenzen, nicht Umsetzung.