Reden statt tippen — warum Spracheingabe nicht in die Cloud gehört
Spracheingabe wird im Alltag erst brauchbar, wenn zwei Dinge zusammenkommen: eine verlässliche Spracherkennung und ein Modell, das den Rohtext strukturiert, ohne ihn neu zu schreiben. Für vertrauliche Arbeit gehört diese Verarbeitung möglichst auf das eigene Gerät. Sonst wird aus einem Produktivitätsgewinn schnell ein DSGVO-Problem.
Die Tastatur ist ausreichend schnell für die Eingabe kurzer Befehle, für längere Texte aber oft zu langsam. Die Sprachsteuerung des Computers stellt eine naheliegende Alternative dar. Die Implementierung dieser Technologie hat sich jedoch aufgrund des erheblichen Aufwands für Nachkorrekturen über die Jahre als wenig effektiv erwiesen.
Ich selbst diktiere seit Langem, auf dem iPhone und dem Mac, und der Befund war immer ähnlich: Man spricht einen Satz und korrigiert anschließend länger, als das Tippen gedauert hätte. Bei Allerweltssätzen ging es notdürftig. Sobald Fachbegriffe, Produktnamen oder Kundenbezeichnungen vorkamen, kam Unbrauchbares heraus. Eigennamen und Fachbegriffe waren typischerweise das, was die Erkennung zuverlässig falsch verstand. Dazu der zweite Dauerärger: Satzzeichen muss man dem Gerät bis heute ansagen. „Komma“, „Punkt“, „neuer Absatz“; man diktiert laut, was man eigentlich nur meint. Das ist 2026 schwer zu rechtfertigen.
Was sich verändert hat
Zwei Entwicklungen treffen jetzt zusammen. Die Erkennung selbst ist deutlich besser geworden, gerade bei Namen und Fachausdrücken. Dahinter kann ein Sprachmodell den Rohtext verbessern: Füllwörter, abgebrochene Anfänge, Satzzeichen, Absätze. Nachkorrigieren wird damit zur Ausnahme statt zur Regel. Erst an diesem Punkt wird Diktat vom Befehlswerkzeug zum Werkzeug für längere Texte.
Dazu kommt eine zweite Verschiebung. Wer mit KI arbeitet, schreibt mehr, nicht weniger: Prompts, Anweisungen, Entwürfe, Rückfragen, Korrekturen. Die Menge an Text, die man einer Maschine mitteilt, ist mit Sprachmodellen sprunghaft gestiegen. Genau dann, wenn mehr Text nötig ist, wird die Tastatur zum finalen Engpass. Der Wechsel auf Sprache wird damit zur Effizienzfrage, besonders in der KI-Arbeit selbst.
Der Haken sitzt im Vertraulichen
Die populären Transkriptionsdienste lösen die Aufbereitung in der Cloud, meist in den USA. Für eine private Einkaufsliste ist das belanglos. Für eine Kunden-E-Mail, einen Vertragsentwurf oder ein Protokoll ist es das nicht. Jedes diktierte Wort wandert auf fremde Server. Wer beruflich mit Vertraulichem arbeitet, müsste das eigentlich vorab klären: Auftragsverarbeitung, Drittlandübermittlung, Löschkonzept, Zugriffskontrolle. Stichwort DSGVO.
Der Normalfall sieht oft anders aus. Man diktiert, der Text erscheint, und dass die Aufnahme dafür extern verarbeitet wurde, bleibt im Alltag unsichtbar. Genau darin liegt das Risiko. Nicht im bewussten Leichtsinn, sondern in einer Gewohnheit, die niemand hinterfragt. Die Frage, wo Daten verarbeitet werden, gehört deshalb vor das erste Diktat, nicht in die Schadensbegrenzung danach.
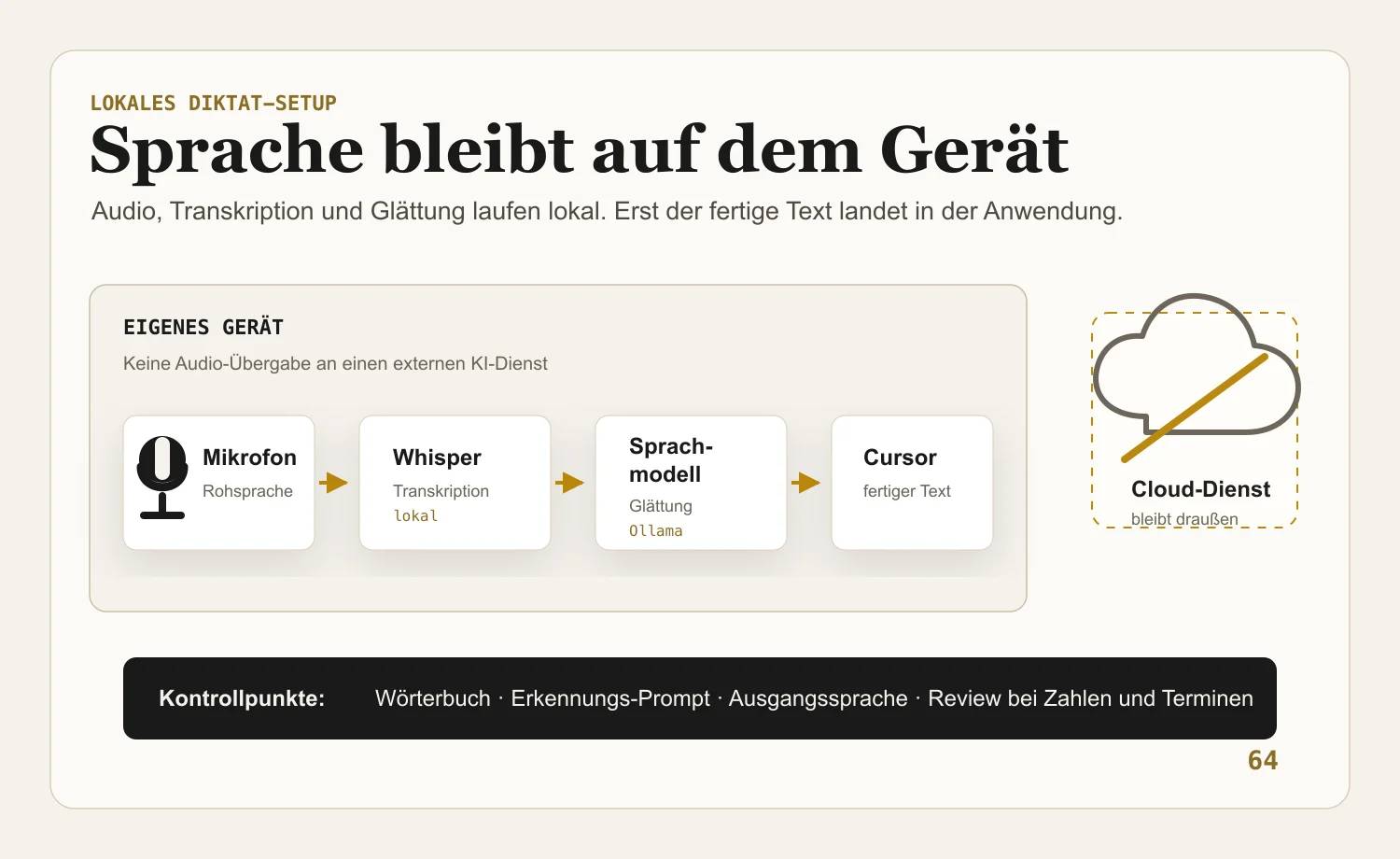
Wie das lokal aussieht
Konkret besteht mein Setup aus drei Teilen. Die Spracherkennung übernimmt ein lokales Whisper-Modell, das vollständig auf dem Mac läuft. Ich nutze die schnelle Large-v3-Variante turbo. Die Aufbereitung übernimmt ein kleines Sprachmodell, ebenfalls lokal installiert; in meinem Fall qwen2.5:7b über Ollama. Die Modellwahl ist austauschbar. Eine kleinere Variante ist schneller und etwas ungenauer, ein größeres Modell braucht mehr Ressourcen. Zusammengehalten wird beides von einem Diktatwerkzeug, in meinem Fall VoiceInk, das die Aufnahme entgegennimmt, durch beide Stufen schickt und den fertigen Text dort einsetzt, wo der Cursor steht.
Ich habe dieses Setup gegen Wispr Flow getestet, einen sehr guten Cloud-Diktatdienst. Bei meinen deutschen Diktaten mit Fachbegriffen lagen die Ergebnisse nah beieinander: Das lokale Setup lieferte vergleichbar gute Texte, ohne dass die Aufnahme dafür an einen externen Dienst gehen musste.
In diesem Setup gibt es keine Audio-Übertragung an einen externen KI-Dienst und keine laufenden API-Kosten für Transkription oder Glättung. Bei Cloud-Diktatwerkzeugen sieht die Rechnung anders aus. Der einfachste Fall ist ein Dienst wie Wispr Flow: Die KI-Verarbeitung ist Teil des Nutzer- oder Team-Abos; Flow Pro kostet laut Preisseite, Stand Juni 2026, je nach Abrechnung 12 bis 15 Dollar pro Nutzer und Monat. Andere Setups nutzen keinen gebündelten Diktatdienst, sondern einen eigenen API-Zugang, etwa zu OpenAI. Dann entsteht neben dem Werkzeug selbst eine variable Nutzungskomponente: Jede Transkription und jede nachgelagerte Textglättung läuft gegen ein Modell und verursacht je nach Anbieter Token-, Minuten- oder Modellgebühren. Lokale Verarbeitung vermeidet all diese API-Kosten und VoiceInk verrechnet eine geringe Einmallizenz.
Datenschutzrechtlich ist lokale Verarbeitung kein Freibrief. Rechtsgrundlage, Löschfristen, Geräteverschlüsselung und Zugriffsschutz bleiben. Aber zwei große Posten fallen weg: keine Auftragsverarbeitung mit einem KI-Anbieter für die eigentliche Sprachverarbeitung, keine Übermittlung der Audiodaten an einen Drittanbieter in diesem Verarbeitungsschritt. Genau daran scheitern Cloud-Diktatwerkzeuge im Beratungsalltag, und genau das entfällt hier.
Drei Stellschrauben aus der Praxis
Ob ein solches Setup im Alltag trägt, entscheidet weniger der Modellname als die Einrichtung. Drei Punkte haben bei mir den Ausschlag gegeben.
Zwei Schichten im Wörterbuch. Korrekturen lassen sich auf zwei Wegen hinterlegen. Der eine ist eine feste Ersetzungsliste, die nach der Erkennung stur greift. Der andere ist ein Vokabular in VoiceInk, das nur das Aufbereitungsmodell zu sehen bekommt und das es nutzen soll, aber nicht garantiert nutzt. Die Konsequenz: Wiederkehrende Eigennamen, die immer gleich falsch ankommen, gehören eher in die feste Liste.
Eigennamen in den Whisper-Prompt. Gemeint ist hier nicht der Prompt an das lokale LLM für die spätere Glättung. Whisper selbst kann vor der Transkription einen kurzen Kontext mit korrekten Schreibweisen bekommen. Wer dort die wichtigsten Namen, Produktbezeichnungen und Fachbegriffe hinterlegt, erhöht die Chance, dass sie schon im Rohtranskript richtig erscheinen. Das lokale LLM arbeitet danach: Es kann Fehler aus dem Transkript noch korrigieren, sollte aber nicht der einzige Ort sein, an dem solche Begriffe erklärt werden.
Die Sprache auf Deutsch stellen. Ein Fallstrick ist nicht offensichtlich: Die Anweisung an das Aufbereitungsmodell ist oft englisch vorformuliert. Übergibt man ihm ein deutsches Diktat ohne die ausdrückliche Vorgabe, in der Ausgangssprache zu bleiben, übersetzt ein größeres Modell den Text bereitwillig ins Englische. Eine klare Zeile im Prompt verhindert das. An solchen Details hängt, ob ein Setup nach einem Tag wieder gelöscht wird oder bleibt.
Wo die Grenzen liegen
Damit dieser Text nicht zur Tool-Werbung wird, gehören die Grenzen dazu. Das Setup ist nicht in jeder Lage überlegen.
Die nachträgliche LLM-Aufbereitung verdreht gelegentlich eine Kleinigkeit. In einem Test wurde aus „nächste Woche“ ein „nächstes Wochenende“. Bei geglättetem Diktat liest man darüber leicht hinweg. Bei Zahlen, Terminen und Namen ist das ein Risiko, das man kennen muss. Wer Treue über Politur stellt, schaltet die Aufbereitung ab, nimmt die rohe, aber originalgetreue Transkription und lebt mit einem gewissen Nachbearbeitungsaufwand. Die feste Ersetzungsliste und der Erkennungs-Prompt greifen dann weiterhin.
Lange Aufnahmen sind damit nicht möglich. Ein ganzes Meeting in einem Stück an ein kleines lokales Modell zu geben, sprengt schnell dessen Kontextfenster. Mehrpersonen-Mitschnitte mit Sprechertrennung, also wer was gesagt hat, leistet ein reines Diktatwerkzeug ohnehin nicht. Bei schwierigem Audio neigt die Erkennung zudem zu Wiederholungsschleifen. Für das Diktat einer einzelnen Person, etwa für typische Anweisungen an eine KI oder für eine E-Mail, funktioniert das Setup heute. Für Konferenzmitschnitte braucht es eine eigene Werkzeugkette, die ebenfalls lokal möglich ist, aber anders aufgebaut werden muss.
Was das für Entscheider heißt
Diktat ist der naheliegende erste Fall einer breiteren Verschiebung: Lokale Modelle sind für klar umrissene Aufgaben gut genug geworden. Das verändert zwei Rechnungen. Die erste sind Kosten, weil laufende Nutzungsgebühren und API-Kosten pro Wort nicht mehr zwingend dazugehören. Die zweite ist Datenschutz, weil eine Anwendungsklasse, die bisher fast automatisch in der Cloud landete, auf das eigene Gerät zurückgeholt werden kann.
Damit ist lokales Diktat ein kleines Beispiel für eine größere Modellstrategie-Frage. Nicht jede KI-Aufgabe gehört lokal. Aber auch nicht jede Aufgabe muss in die Cloud, nur weil es dort bequemer aussieht. Die praktische Frage für die nächsten Jahre lautet deshalb: Welche Arbeiten, etwa Zusammenfassen, Extrahieren oder Strukturieren, lassen sich lokal erledigen, ohne dass Qualität oder Bedienbarkeit merklich leiden? Wer das früh prüft, verschiebt die Grenze zwischen „muss extern laufen“ und „bleibt im Haus“ zu seinen Gunsten.