Wo gute KI-Use-Cases liegen — und wie man sie erkennt
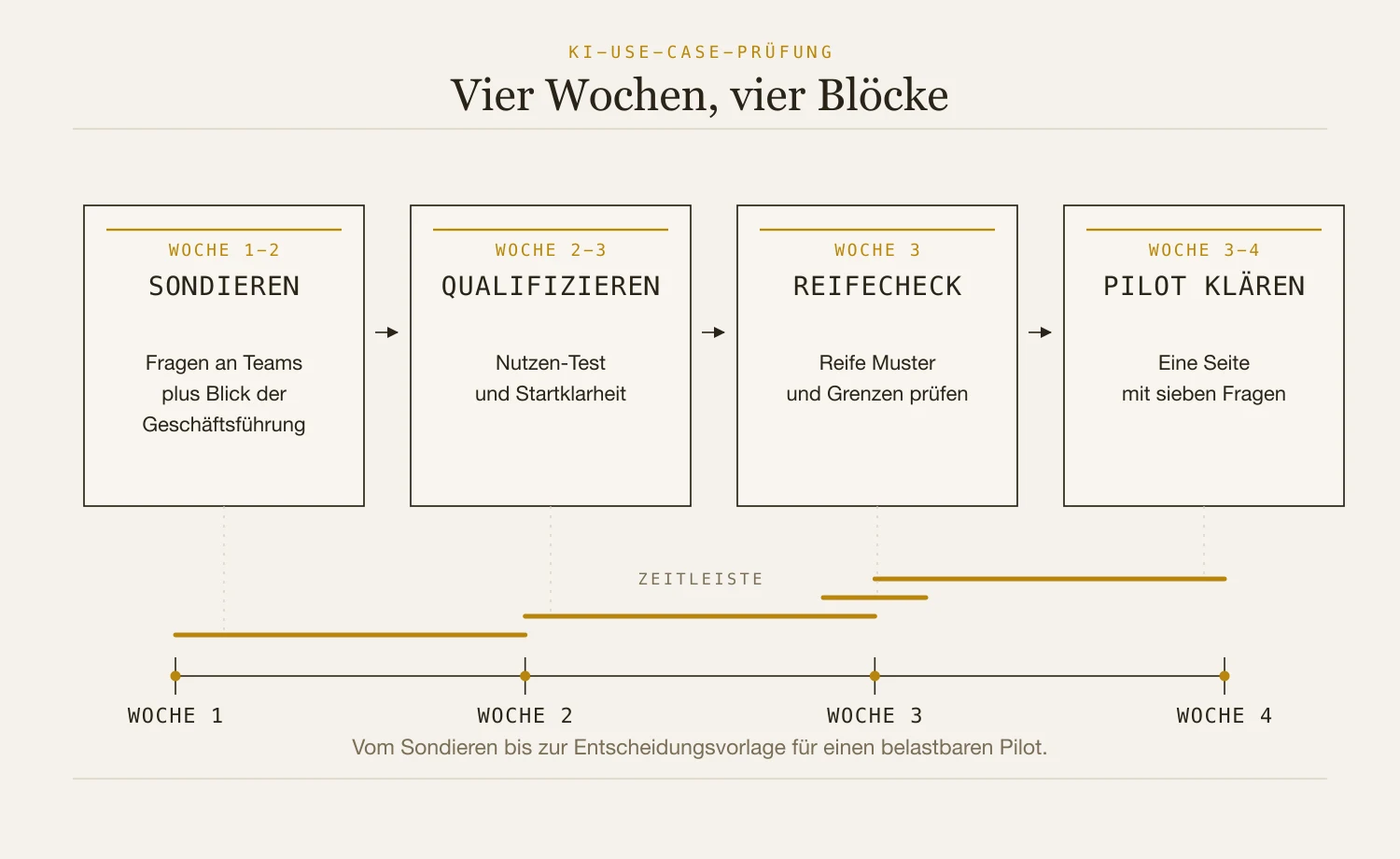
Viele KI-Workshops enden mit Wunschlisten. Die Ideen klingen plausibel, doch Monate später ist kaum etwas produktiv. Das Problem liegt selten an fehlender Kreativität. Es liegt an der Reihenfolge: Erst werden Einsatzideen gesammelt, dann wird geprüft, ob Daten, Prozess, Verantwortung und Messgröße überhaupt vorhanden sind. Tragfähige KI-Use-Cases entstehen anders. Sie beginnen bei wiederkehrender Arbeit, messbarem Ergebnis und einem klaren wirtschaftlichen Hebel. Dieser Beitrag beschreibt eine Vier-Wochen-Methode: sondieren, qualifizieren, Reife prüfen, Pilot klären.
Am Anfang steht oft eine einfache Frage: Wo sollte KI im Unternehmen zuerst eingesetzt werden? Die übliche Antwort ist ein Workshop mit Ideensammlung und Priorisierung. Das Ergebnis sieht geordnet aus, bleibt aber häufig unverbindlich. Nach sechs Monaten ist unklar, welcher Kandidat tatsächlich läuft.
Das ist kein Pech. Das ist ein Konstruktionsfehler. Use-Cases werden nicht durch Brainstorming gefunden, sondern durch Beobachtung der Arbeit. Danach braucht es einen Filter, der nüchtern trennt: Was ist ein wirtschaftlich relevanter KI-Kandidat, was ist nur eine gute Idee?
Die Methode beruht auf einer einfachen These. Nach heutigem Stand trägt ein KI-Use-Case nur, wenn sechs Bedingungen zusammenkommen. Drei Kriterien machen die Aufgabe KI-fähig:
- Die Tätigkeit wiederholt sich häufig, nicht nur einmal im Quartal.
- Der Ablauf ist klar beschreibbar — Input, Schritte, Output sauber benannt.
- Die nötigen Daten liegen sauber und zugreifbar vor, in ausreichender Menge und Qualität.
Drei weitere machen den Use Case wirksam:
- Er zahlt auf ein Geschäftsziel konkret ein.
- Der Output ist messbar — nach dem Durchlauf lässt sich prüfen, ob das Ergebnis stimmt.
- Dieser messbare Output fließt als Qualitätsschleife zurück — in bessere Prompts, geschärfte Wissensbasis, angepasste Schwellenwerte, klarere Review-Regeln — damit das System mit der Zeit besser wird statt schlechter.
Fehlt eines der sechs Elemente, kann das Thema trotzdem wichtig sein. Es ist dann aber oft kein guter KI-Use-Case für aktuelle Modelle. Der Filter wirkt streng. Er erspart einem aber den Pilot-Friedhof.
Dieser Standardpfad gilt für operative Use-Cases mit hoher Frequenz. Für seltene Fälle mit hohem Einzelwert — Ausschreibungen, M&A, Krisenanalysen — reicht ein wiederverwendbarer Ablauf. Dort ersetzt der Wert des einzelnen Falls die Häufigkeit.
Block 1 — Sondieren, Wochen 1 und 2
Die ersten beiden Wochen bleiben bewusst ohne KI-Vokabular. Keine Tool-Namen, keine Modellvergleiche, keine Copilot-Demo. Wer nach KI fragt, bekommt Meinungen über KI. Wer nach Arbeit fragt, findet die möglichen Einsatzpunkte. Entscheidend sind Gespräche mit den Rollen, die nah an der operativen Arbeit sind: Buchhaltung, Vertriebsinnendienst, Kundenservice, Rechtsabteilung. Fünf Fragen reichen für den Einstieg:
- Welche Tätigkeiten kehren täglich oder wöchentlich wieder — immer mit ähnlichem Ablauf?
- Wo entstehen regelmäßig Entscheidungen auf Basis von Daten, die heute manuell gesichtet oder verdichtet werden?
- Wo ist monotone Genauigkeit gefragt — viele Vorgänge, Anfragen oder Auswertungen?
- Welche Standardfälle treten wieder auf, bei denen die Antwort im Haus eigentlich schon existiert und nur gering modifiziert werden muss?
- Wo ist die Durchlaufzeit deutlich länger als die eigentliche Arbeit — weil jemand recherchieren, nachfragen oder zusammentragen muss?
Diese fünf Fragen zielen auf Struktur im Alltag. Sie finden Tätigkeiten, die häufig wiederkehren, beschreibbare Abläufe haben, auf Daten beruhen oder lange Durchlaufzeiten erzeugen. Genau dort kann KI heute einen Hebel ansetzen.
Interviews finden allerdings nicht alles. Eine zweite Kategorie rutscht leicht durch: Fälle, in denen Wert verloren geht, ohne dass das Team es im Tagesgeschäft bemerkt. Eine Vertriebsmannschaft hält fünf Tage Reaktionszeit auf Ausschreibungen für normal, während ein Wettbewerber nach 24 Stunden antwortet. Die Qualität von Due-Diligence-Berichten sinkt langsam, weil Experten zu wenig Zeit für Review haben. Solche stillen Verluste zeigen sich nicht in der Frage, welche Arbeit nervt. Sie zeigen sich im Vergleich mit Markt, Wettbewerb und Risiko. Deshalb braucht die Sondierung auch Fragen an die Geschäftsführung:
- Wo verlieren wir Kunden, Umsatz oder Qualität, ohne dass es im Team auffällt?
- Wo geht uns Geschwindigkeit gegenüber Wettbewerbern verloren?
- Wo wachsen bei uns Risiken unbemerkt — Compliance-Drift, Haftung, Reputationsschäden?
- Wo könnten mit KI Angebote oder Geschäftsmodelle entstehen, die heute an Kapazität oder Auswertungstiefe scheitern?
Dazu kommt direkte Beobachtung. Einige Stunden neben Schlüsselrollen sitzen, nicht nur Interviews führen. Ein Blick in Systeme zeigt oft mehr als ein Workshop: Welche Themen wiederholen sich im Ticket-Tool? Wo liegt Arbeit seit drei Tagen im Mail-Backlog? Wie lange braucht eine neue Kraft bis zur ersten produktiven Stunde? Welche Fehler oder Beschwerden kommen immer wieder?
Am Ende von Block 1 liegen typischerweise 15 bis 25 Kandidaten vor. Der letzte Schritt ist ein grober Compliance-Screen: Welche Kandidaten berühren Berufsgeheimnis, DSGVO-Hochrisikozonen, BaFin-Pflichten oder betriebsratspflichtige Arbeitsprozesse? Solche Kandidaten fallen nicht automatisch weg. Sie brauchen später ein anderes Setup als unkritische Fälle.
Block 2 — Qualifizieren, Woche 2 bis 3
Jetzt folgt der Filter. Ein Kandidat, bei dem eines der sechs Grundkriterien klar fehlt, ist kein guter KI-Use-Case. Das ist nicht pessimistisch, sondern eine Kostenkontrolle.
Die verbleibenden Kandidaten laufen durch zwei Prüfungen. Die erste ist der Nutzen-Test. Was hier durchfällt, sollte nicht pilotiert werden.
- Der Nutzen ist groß genug. Der erwartete Effekt muss den Aufwand eines Piloten rechtfertigen — etwa durch Einsparpotenzial, zusätzlichen Umsatz oder schnellere Reaktionszeiten.
- KI-Output ist validierbar. Eine Berechnung ist validierbar. Eine Software funktioniert oder hat Bugs. Ein Ticket ist gelöst oder wird eskaliert. Wenn der Output nur rein subjektiv ist („die Antwort klingt gut"), fehlt die notwendige Korrekturschleife.
- Fehlerfolgen sind tragbar. Die kritische Frage lautet: Was passiert, wenn die KI daneben liegt? Korrigiert ein Mensch ohnehin — Entwurf, Vorschlag — dann ist eine höhere Fehlerquote vertretbar. Wird die KI-Entscheidung direkt umgesetzt, muss Schadenshöhe mal Fehlerwahrscheinlichkeit tragbar sein. Eine automatische Kontobuchung bei 10 Prozent Fehlerquote ist eine andere Liga als ein Antwortvorschlag, den eine Supportmitarbeiterin ohnehin noch prüft.
Die zweite Prüfung betrifft die Startklarheit. Was hier durchfällt, ist nicht zwingend ungeeignet. Es braucht Vorarbeit, bevor ein Pilot sinnvoll ist.
- Ausreichende Dokumentation vorhanden. Gibt es genug historische Fälle, eine saubere Prozessdokumentation usw., an denen die KI aufgesetzt und angelernt werden kann?
- Digitales Wissen vorhanden. Liegt das Wissen (die Daten) maschinenlesbar vor? Scans in E-Mail-Anhängen und Papier im Aktenschrank sind kein KI-geeignetes digitales Material. Hier ist Vorarbeit erforderlich.
- Zugriff auf das Wissen ist geklärt. Wer darf was lesen? Wie lange dauert die Freigabe durch IT, Sicherheit, Datenschutz? Ist sichergestellt, dass kein vertrauliches Wissen offengelegt wird?
- Verantwortung und Budget sind geklärt. Ohne Budgetverantwortung ist der Kandidat nicht tot. Er startet nur nicht.
- Compliance geklärt. Ist die Rechte-Hürde aus Block 1 in vertretbarem Aufwand zu lösen, oder braucht es erst noch längere Vorarbeit?
Ein Kandidat kann wirtschaftlich attraktiv sein und trotzdem an der Startklarheit hängen. Das ist eine andere Diagnose als „nicht KI-geeignet“. Häufig ist sie wichtiger, weil sie konkrete Arbeit an Infrastruktur, Datenzugriff oder Prozessklärung auslöst.
Ein Zusatztest hilft: Lässt sich die Aufgabe so beschreiben, dass ein neuer Mitarbeiter sie übernehmen könnte? Wenn ja, ist sie meist klar genug für KI. Wenn nein, liegt der Engpass bei der Prozessklarheit, nicht bei der Technologie. Kein Modell stellt diese Klarheit im Piloten nachträglich her.
Block 3 — Reifecheck, Woche 3
Nach den ersten beiden Blöcken liegen qualifizierte Kandidaten vor. Jetzt folgt der Abgleich mit dem, was aktuelle Modelle verlässlich können. Nicht alles, was plausibel klingt, ist produktionsnah umsetzbar.
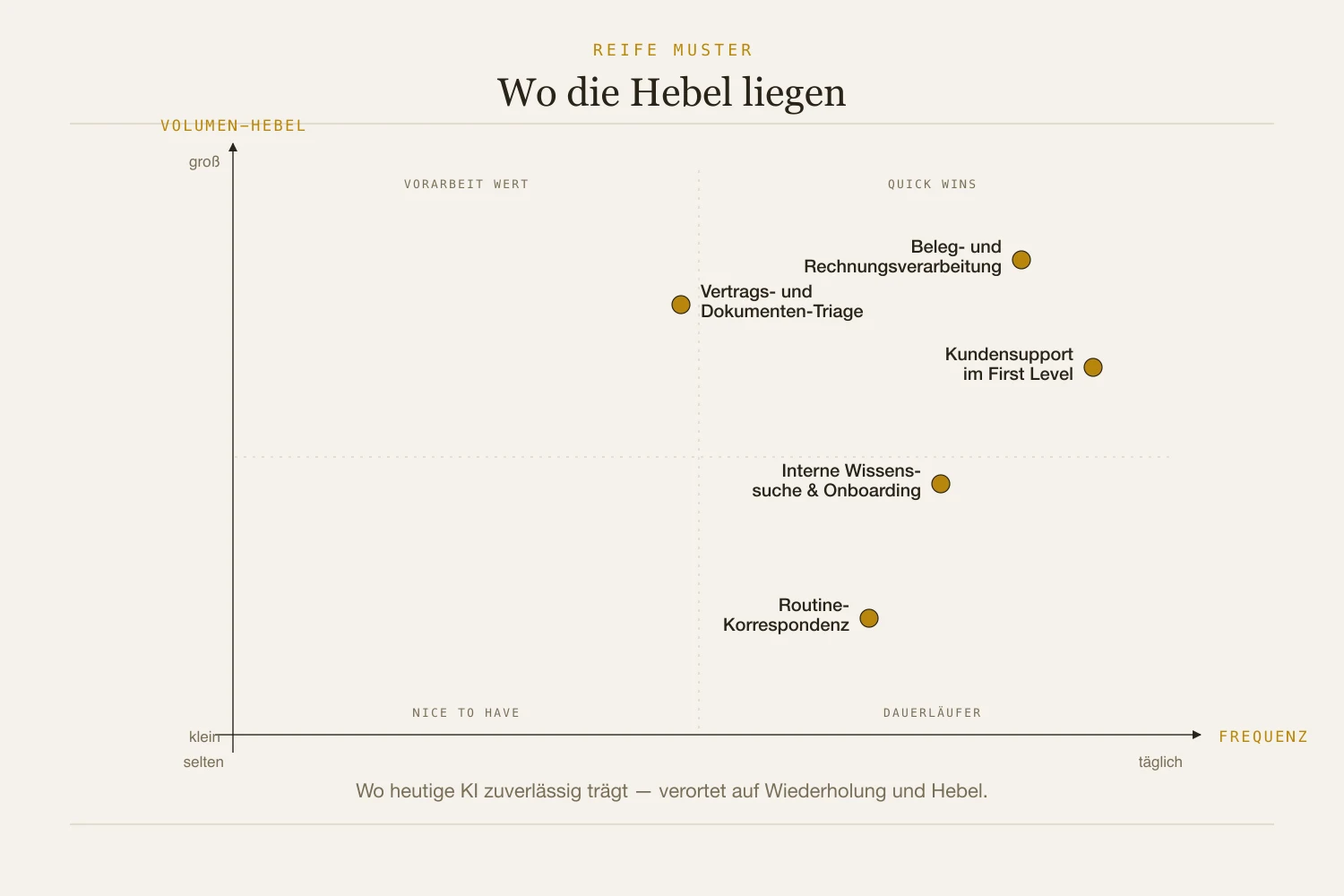
Einige Muster funktionieren Stand heute. Allerdings jeweils in einer bestimmten Betriebsart. Die Einordnung ist ein Standbild aus Frühjahr 2026, kein dauerhaftes Ranking.
Beleg- und Rechnungsverarbeitung. Produktiv im Assist-Modus und in kontrollierter Teilautomatisierung für Standardbelege. JP Morgan berichtet bei Prysmian über Fehlerquoten unter einem Prozent bei sauberen Formaten; bei komplexen oder ungewöhnlichen Formaten fällt die Genauigkeit oft unter 70 Prozent. Das ist etwas anderes als Straight-through-Automatisierung ohne Kontrolle.
Kundensupport 1st-Level. Produktiv im Assist-Modus für Supportmitarbeiter: Die KI schlägt aus Historie und Wissensbasis eine Antwort vor, der Mensch entscheidet. Auto-Antwort funktioniert nur für eng definierte Standardfälle. Der Klarna-Fall zeigt die Grenze. Der Vorzeigefall von 2024 — 2,3 Millionen Gespräche pro Monat, 700 ersetzte Vollzeitstellen — kippte 2025 zurück auf ein Hybridmodell. CEO Sebastian Siemiatkowski sagte: „Cost was a predominant evaluation factor — it resulted in lower quality.“ Ein Warnfall, bevor Unternehmen den Auto-Modus freischalten.
Vertrags- und Dokumenten-Triage. Produktiv für Klausel-Extraktion und Abweichungshinweise. Luminance analysiert 700 Verträge auf Tarifänderungen in unter zwei Stunden statt zweieinhalb Wochen; Harvey erreicht 94,8 Prozent Genauigkeit bei Document-Q&A. Nicht zu verwechseln mit Rechtsbewertung oder Verhandlungsposition — die Haftung bleibt beim Menschen, die KI liefert Roh-Triage. Die Frequenz variiert stark nach Branche: in Kanzleien, Procurement, Legal Ops, Versicherungen und regulierten Konzernen Tagesgeschäft, in anderen Häusern Einzelfall.
Interne Wissenssuche und Onboarding. Produktiv als Frage-Antwort-System gegen die eigene Wissensbasis, mit Quellenangabe. Morgan Stanley berichtet 98 Prozent Adoption bei den Financial Advisors, Antworten streng gebunden an interne Quellen. Voraussetzung: gepflegte Wissensbasis und saubere Zugriffsrechte — Microsoft warnt selbst vor Oversharing bei 70 Prozent der 100 meistgenutzten SharePoint-Sites. Nicht zu verwechseln mit autoritativen Antworten ohne Quellennachweis.
Routine-Korrespondenz mit Kontext. Produktiv als Entwurfsstufe: Der Mensch schreibt fertig, die KI liefert den ersten Wurf. Der UK Civil Service misst in einem Trial mit 20.000 Nutzern 26 Minuten Zeitersparnis pro Tag. Der Hebel pro Einzelfall ist klein; über viele Rollen und tägliche Wiederholung wird daraus ein relevanter Produktivitätsposten. Das ist nicht Auto-Versand. Besonders heikel sind Finanztexte: Hudson Labs testete im September 2025 GPT-5 auf Finanzfragen, nur eine von 25 Antworten war korrekt. Fabrizierte Zahlen sind ohne Quellenverifikation „almost impossible to identify“.
Was nicht trägt, gehört ebenfalls auf die Liste. Use-Case-Workshops landen regelmäßig bei Themen, die besser klingen als sie funktionieren. Stand April 2026 gehören dazu: vollautonome agentische End-to-End-Workflows ohne menschliche Kontrolle, kreative Positionierungs- und Strategiefragen, Entscheidungen mit hoher persönlicher Haftung ohne Review. Das sind keine guten Felder für den nächsten Piloten.
Was der Standardpfad nicht automatisch findet
Die fünf Muster sind ein Reife-Stand, keine abschließende Liste. Drei Kategorien tauchen bei Sondierung und Qualifizierung weniger leicht auf, können aber trotzdem tragen. Strategische Einzelfälle mit hohem Wert — etwa M&A-Due-Diligence, große Ausschreibungen oder Krisenanalysen — sind keine Dauerläufer, aber wiederverwendbare Abläufe. Dort ersetzt Einzelwert die Frequenz und Review die binäre Messung. Qualitative Assistenz bei Ideenvarianten, Übersetzung oder Tonalität trägt, wenn der Output nachvollziehbar beurteilt werden kann. KI-native Workflows wie synthetische Kundensegmente, Live-Übersetzung in Meetings oder multimodale Analyse entstehen neu und passen noch nicht sauber in die fünf Muster.
Ein weiterer Fall muss nicht gesucht werden, weil er meist schon existiert: Mitarbeiter nutzen ChatGPT oder Claude privat auf dem Arbeitsrechner. Das ist kein Use-Case, sondern ein Governance-Signal. IT und Geschäftsführung müssen entscheiden, wie daraus ein kontrollierter Umgang wird, bevor ein Datenschutzproblem entsteht.
Block 4 — Pilot klären, Woche 3 bis 4
Nach drei Wochen bleiben typischerweise drei bis fünf Kandidaten übrig. Sie haben wirtschaftlichen Nutzen, sind grundsätzlich startklar und passen zu einem reifen Muster. Trotzdem sollte noch kein Pilot starten. Genau an dieser Stelle scheitern viele Initiativen: Der Kandidat wird nicht zu Ende gedacht, bevor das erste Tool angefasst wird.
Vor dem Start braucht es eine Entscheidungsvorlage auf einer Seite. Sie beantwortet sieben Fragen. Bleiben mehrere davon offen, ist der Pilot noch nicht reif.
- Wer ist verantwortlich? Ein Name, kein Gremium. Wer trifft Entscheidungen, wenn es eng wird?
- Was ist der Ausgangswert? Messbare Größe: Durchlaufzeit, Fehlerquote, Kosten pro Fall, Volumen. Ohne Ausgangswert ist Erfolg nicht messbar.
- Was ist das Erfolgskriterium? Eine Zahl, vor dem Piloten festgelegt. „30 Prozent kürzere Durchlaufzeit" oder „Fehlerquote unter zwei Prozent" — nicht „gefühlt besser".
- Welches Material und welcher Zugriff? Liegen die Daten systemseitig? Wer gibt frei? Wie lange dauert die Freigabe?
- Welche rechtliche Hürde, welches Modell, welches Hosting? Hier liegt oft die schwierigste Frage für europäische Unternehmen — und sie fällt pro Use-Case anders aus, nicht pauschal pro Haus.
Zur Rechte-Hürde gehören DSGVO, Betriebsrat, Berufsrecht in Kanzleien und Steuerberatungen, BaFin bei Banken, MDR in der Medizintechnik. Parallel dazu die Entscheidung über Modell und Hosting. Drei Setups stehen 2026 realistisch zur Verfügung:
| Setup | Qualität | Compliance-Aufwand | Typisch sinnvoll für |
|---|---|---|---|
| US-Frontier Claude (Anthropic), ChatGPT (OpenAI), Gemini (Google) — optional in EU-Region von Azure/AWS | hoch | DSGVO-fähig mit AVV und EU-Data-Boundary — aufwendig, aber etabliert | komplexe Assist-Aufgaben, interne Wissenssuche, Routine-Korrespondenz mit menschlicher Freigabe |
| EU-Anbieter Mistral — oder EU-gehostete Varianten von US-Modellen | merklich dahinter am Frontier, für Standardaufgaben ausreichend | einfacher zu rechtfertigen | sensible Daten, Standard-Komplexität |
| Open Source on-prem Gemma (Google), Qwen (Alibaba), Llama (Meta) | variabel, die besten kommen näher, spürbare Lücke bleibt; hoher Engineering-Aufwand | volle Kontrolle über Daten und Modell | hochsensibles Material (Berufsgeheimnis, Personaldaten, strategische Pläne) |
Zwischen den führenden Frontier-Modellen — Claude, ChatGPT, Gemini — und vielen Alternativen liegt aktuell ein sichtbarer Qualitätsabstand: bei komplexen Aufgaben größer, bei Standardaufgaben kleiner. Qwen ist ein starkes Modell aus China; für europäische Entscheider ist die Herkunft kein Ausschlussgrund, aber eine bewusste Governance-Entscheidung. Die Landschaft verschiebt sich schnell. Diese Einordnung trifft den Stand Frühjahr 2026.
Eine pauschale Vorgabe „alles Open Source, alles in Europa“ senkt in manchen Fällen die Ergebnisqualität so weit, dass der Business Case nicht mehr trägt. Eine pauschale Vorgabe „alles US-Frontier, egal wie“ kann dagegen das nächste Datenschutzproblem erzeugen. Die belastbare Antwort liegt meist pro Use-Case dazwischen.
- Wer prüft menschlich? Welche Rolle kontrolliert die KI-Ergebnisse in welcher Taktung? Das ist der operative Kontrollpunkt, nicht Theorie.
- Welches Budget, welcher Zeitraum? Größenordnung — 5.000, 50.000, 500.000 Euro — und fester Endpunkt: vier bis sechs Wochen, dann Go/No-Go. Kein offenes Ende.
Wenn alle sieben Antworten vorliegen, kann der Pilot starten. Wenn mehrere Punkte offen sind, kommt zuerst die Vorarbeit.
Drei Fehler, die sich wiederholen
- Tool-Reflex. „Wir haben jetzt Copilot-Lizenzen, also müssen wir Use-Cases finden.“ Die Reihenfolge ist umgekehrt: erst der Use-Case, dann das Tool. Eine Lizenz ohne klares Problem ist oft nur eine teure Suchmaschine.
- Workshop-Reflex. Brainstorming statt Beobachtung. Am Konferenztisch taucht meist nur auf, was ohnehin bekannt war. Die interessanten Use-Cases liegen in den Arbeitsabläufen.
- Leuchtturm-Reflex. Der schwierigste Use-Case kommt zuerst, weil er am spannendsten klingt. Das Ergebnis ist oft ein Projekt, das zwei Jahre braucht, zwischendurch niemand wirklich betreibt und nach dem Scheitern die Organisation vorsichtiger macht als zuvor. Kleine produktive Fälle sind weniger spektakulär, aber sie zeigen, wie eine Organisation mit KI arbeitet.
Warum dieses Bild
Zwei Studien stützen die Richtung. McKinsey State of AI 2025 ↗ berichtet, dass nur 21 Prozent der Unternehmen ihre Workflows grundlegend neu gestalten — genau dort entsteht der messbare EBIT-Impact. BCGs 10-20-70-Regel ↗ kommt aus anderer Richtung zum selben Bild: 70 Prozent des Werts liegen in People und Process, nur 10 in Algorithmen. Die Tool-Frage ist nicht die Engstelle. Entscheidend ist, welche Arbeit verändert wird und wie.
Der KI-Assistent wird austauschbarer. Dieselben Modelle, ähnliche Preise, ähnliche App-Stores. Was Unternehmen unterscheidet, ist nicht das Modell, das sie mieten. Es ist die Disziplin, vor dem ersten Tool die Arbeit, die Daten, die Verantwortung und die Messgröße zu klären. Vier Wochen, vier Blöcke, sieben Fragen. Davor gibt es keine Abkürzung. Wer anderes verspricht, verkauft meist Lizenzen, nicht Umsetzung.